filter
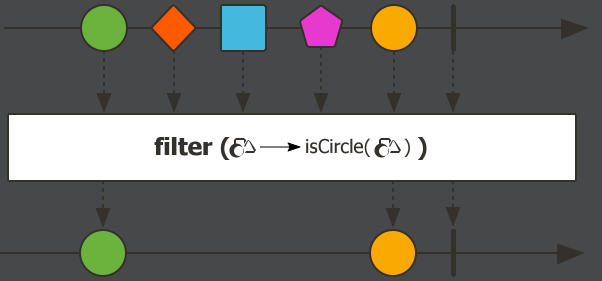
filter,过滤。能把原来流里的元素按照一定的规则过滤出来,然后组成一个新流。
Flux.just(1,2,3,4) .log() .filter(i -> i % 2 == 0) .subscribe();执行结果:

flatMap
-
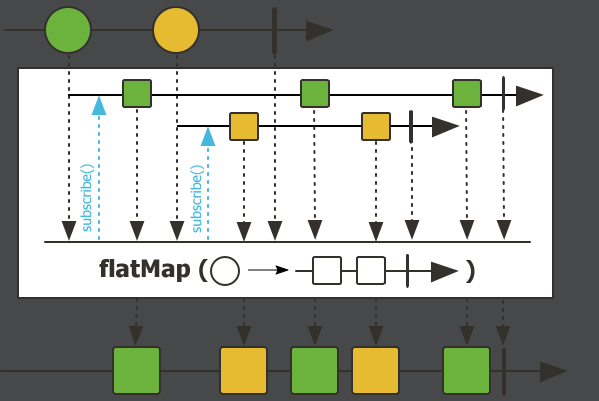
flatMap,扁平化作用,把数据包装成多元素流。flatMap可以把原来流里的元素拆分成多个元素再组成一个新流。Flux.just("zhang san", "li si") .log() .flatMap(v ->{ String[] s = v.split(" "); return Flux.fromArray(s); }) .subscribe();先把
log打在开始看看流原来是怎么样子的:
流里现在是两个元素:
zhang san、li si。接下来把
log打在flatMap之后看看流的变化:Flux.just("zhang san", "li si") .flatMap(v ->{ String[] s = v.split(" "); return Flux.fromArray(s); }) .log() .subscribe();执行结果:
流的元素已经变成四个了。

concat
-
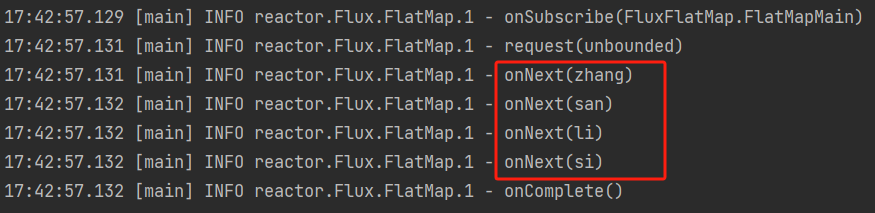
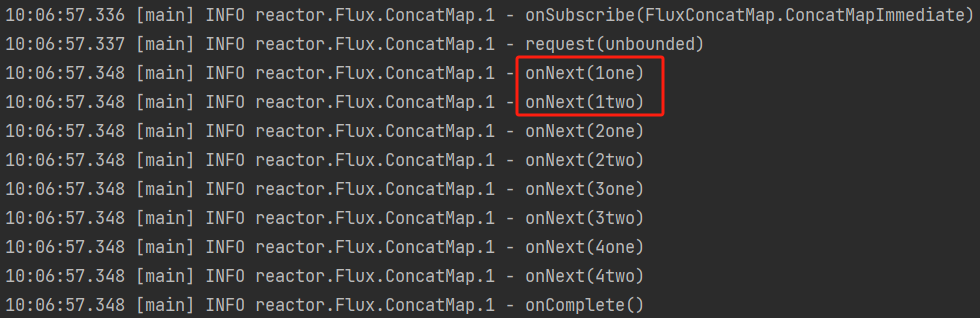
concatMap,按照源流中元素的顺序依次处理每个元素的映射流,并将这些映射流的结果按顺序合并成一个单一的流。Flux.just(1,2,3,4) .log() .concatMap(s -> Flux.just(s + "one",s + "two")) .subscribe();先看下流一开始的元素:
接下来把
log打在flatMap之后看看流的变化:Flux.just(1,2,3,4) .concatMap(s -> Flux.just(s + "one",s + "two")) .log() .subscribe();执行结果:
concatMap可以把两个流的元素“相乘”,得出一个新的流。 -
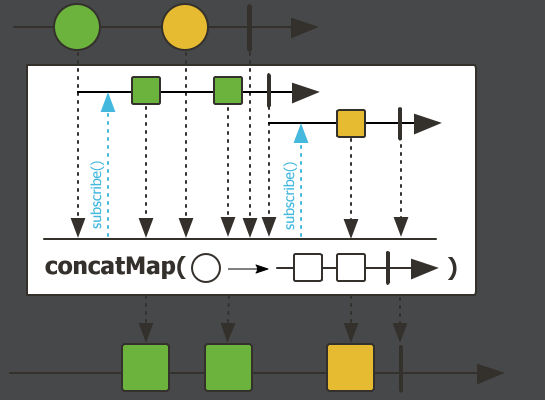
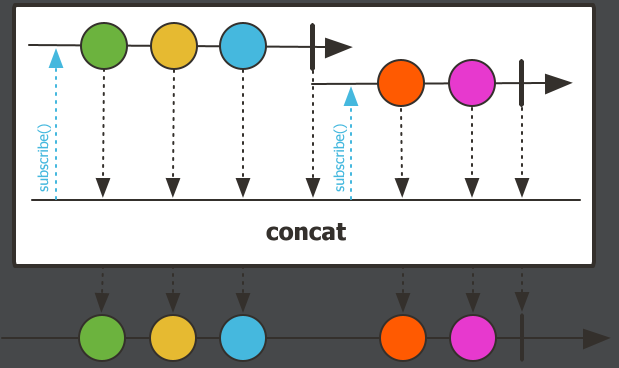
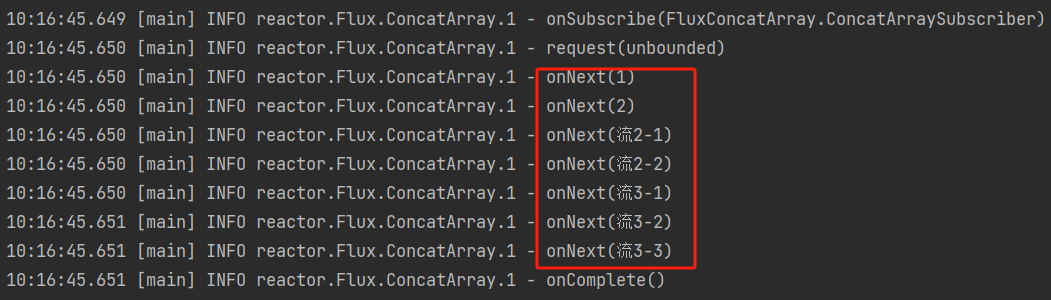
concat,连接操作。把多个流拼接起来组成一个新流。Flux.concat(Flux.just(1,2),Flux.just("流2-1","流2-2"),Flux.just("流3-1","流3-2","流3-3")) .log() .subscribe();执行结果:
把3个流的元素不做任何操作拼接起来了,跟拼接字符串一样。
-
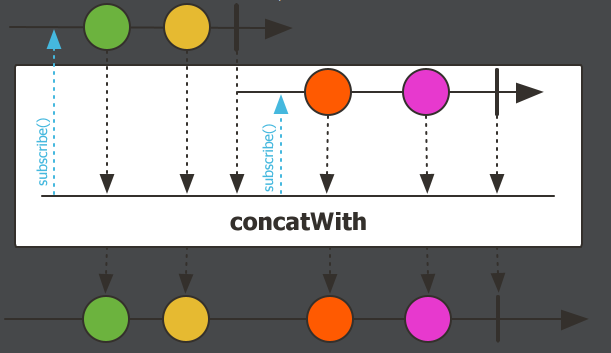
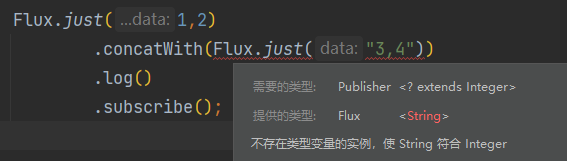
concatWith,连接操作。把老流和新流拼接起来组成一个新流。Flux.just(1,2) .concatWith(Flux.just(3,4)) .log() .subscribe();执行结果:
与
concat的区别:
concat不需要原来有流,是Flux的静态调用。而
concatWith需要原来有一个老流,才能调用。且老流与新流的元素类型要一致。比如老流的元素是整型的,新流也要是整型,字符串类型同理。


transform
-
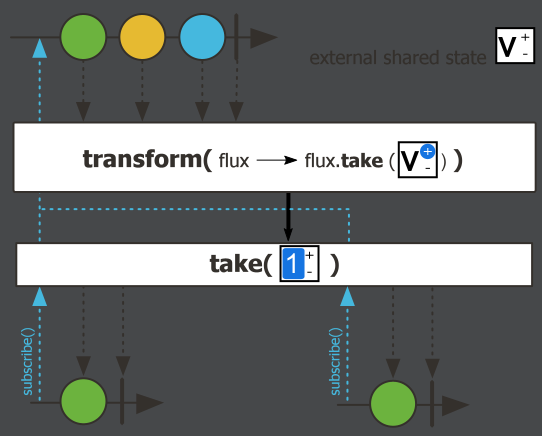
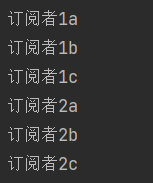
transform,无状态转换。无论有多少个订阅者,transform只执行一次。Flux<String> flux = Flux.just("A", "B", "C") .transform(originalFlux -> originalFlux.map(String::toLowerCase)); flux.subscribe(v -> System.out.println("订阅者1" + v)); // 输出:a, b, c flux.subscribe(v -> System.out.println("订阅者2" + v)); // 输出:a, b, c执行结果:
-
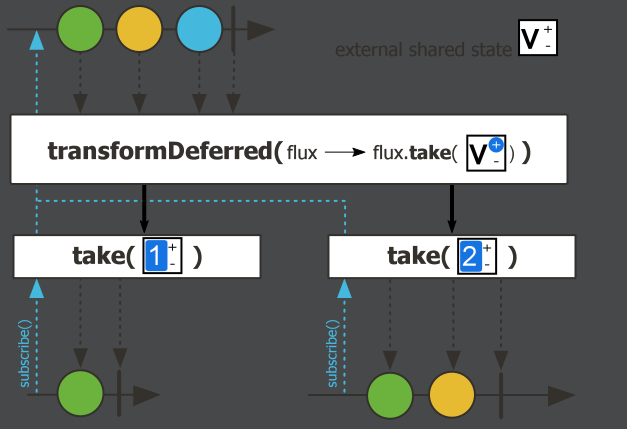
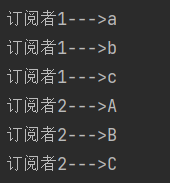
transformDeferred,有状态转换,每个订阅者订阅的时候,transform都会重新执行一次。AtomicInteger counter = new AtomicInteger(); Flux<String> flux = Flux.just("A", "B", "C") .transformDeferred(values -> { if (counter.incrementAndGet() == 1) { return values.map(String::toLowerCase); } return values; }); flux.subscribe(v -> System.out.println("订阅者1--->" + v)); // 输出:a, b, c flux.subscribe(v -> System.out.println("订阅者2--->" + v)); // 输出:a, b, c*/执行结果:
transformDeferred与transform的区别:transform执行过程:transform方法在Flux创建时就应用了变换操作,这意味着变换操作在所有订阅者之前只会应用一次。同样的代码如果使用
transform代替transformDeferred,那么流程逻辑是:- 创建 Flux:
Flux.just("A", "B", "C")创建一个包含字符串 “A”, “B”, “C” 的流。transform方法在流创建时应用一次变换操作。counter.incrementAndGet()调用时计数器增加到 1。
- 变换逻辑:
- 因为计数器值是 1,所以变换操作将流中的字符串转换为小写,并返回变换后的
Flux。
- 第一次订阅:
- 订阅时,流输出
a, b, c。
- 第二次订阅:
- 再次订阅时,计数器增加到 2,但变换操作已经应用完毕,不会再次执行。既不会再次执行以下代码:
(values -> { if (counter.incrementAndGet() == 1) { return values.map(String::toLowerCase); } return values; }); - 因此,第二次订阅时输出还是
a, b, c。
transformDeferred执行过程:在每次订阅时重新应用变换操作。- 创建 Flux:
Flux.just("A", "B", "C")创建一个包含字符串 “A”, “B”, “C” 的流。
- 第一次订阅:
- 订阅时,
transformDeferred应用变换操作。 counter.incrementAndGet()调用时计数器增加到 1。- 因为计数器值是 1,流中的字符串被转换为小写,输出
a, b, c。
- 第二次订阅:
- 再次订阅时,
transformDeferred重新应用变换操作。 counter.incrementAndGet()调用时计数器增加到 2。- 因为计数器值不是 1,流中的字符串保持原样,输出
A, B, C。
总结:
- 使用
transform时,变换操作在流创建时应用一次,所有订阅者都会看到相同的变换结果。 - 使用
transformDeferred时,每次订阅都会重新应用变换操作,允许根据计数器的值动态决定如何处理流中的数据。
Empty
-
defaultIfEmpty,静态兜底数据。检查流是否为空,如果为空,则指定默认值,否则用发布者的值Mono.just("aaa").defaultIfEmpty("x").subscribe(System.out::println);这时候流有一个元素
aaa,所以执行结果为:
当流为空时:
Mono.empty().defaultIfEmpty("x").subscribe(System.out::println);执行结果:
当流为空时,就会替换成默认的值
x。这里有一个注意的点:
Mono.just(null):流里面有一个null值元素,流不为空。Mono.empty():流里面没有元素,只有 完成/结束信号,流为空。 -
switchIfEmpty,检查流是否为空,如果为空,则调用动态兜底方法,返回新流数据。
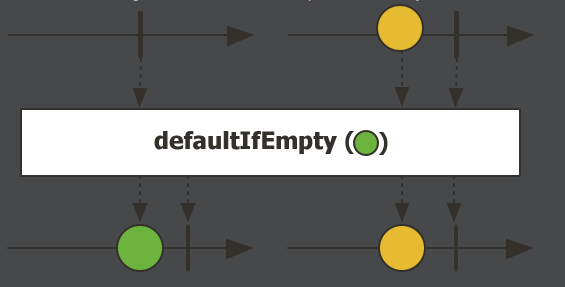


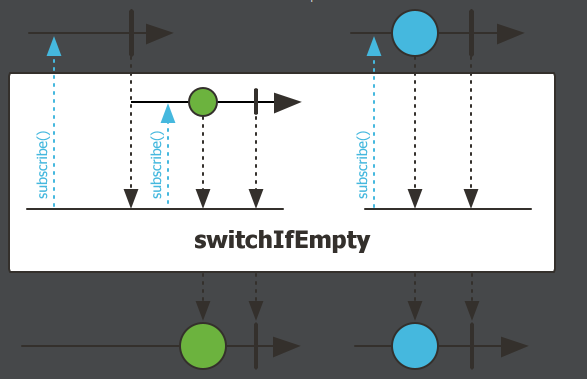
Mono.empty().switchIfEmpty(haha()).subscribe(System.out::println);
---------------------------------------
static Mono<String> haha(){
return Mono.just("兜底方法……");
}
执行结果:
merge
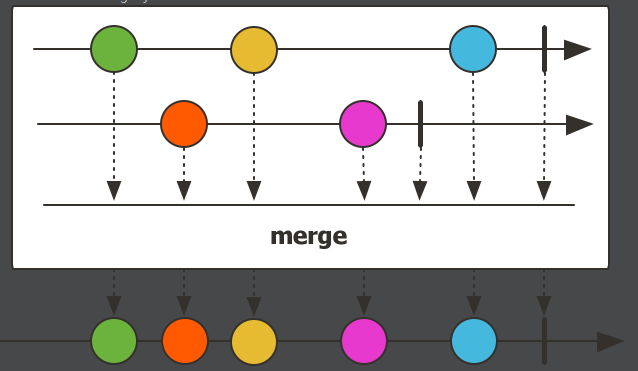
merge,合并操作。用于将多个流的数据流合并到一个新流中,与concat方法不同,merge方法会并行地订阅所有的流,并交错地将它们的元素发射出来。这意味着它可以并行处理数据流,而不必等到一个流完全结束后再处理另一个流。也就是说,在所有订阅发布者流中,按照所有发布者发布元素时间顺序,来合并到新流中,先到先得。merge是合并,而concat是连接。Flux.merge( Flux.just(1,2,3).delayElements(Duration.ofMillis(1000)), // 流1 Flux.just("A","B","C").delayElements(Duration.ofMillis(1500)), // 流2 Flux.just("one","two","three").delayElements(Duration.ofMillis(500)) //流3 ) .log() .subscribe();这3个发布者流的发布速度都不一样,流1是一秒发一次,流2是1.5秒发一次,而流3则是0.5秒发一次。
执行结果:
执行顺序为:流3->流1->流2,而合并到新流则是按照先到先得的顺序。
如果是用
concat,这里的顺序则应该是:1,2,3,A,B,C,one,two,three。-
mergeWith,则与concatWith类似。需要原来有一个老流,才能调用。且老流与新流的元素类型要一致。不过mergeWith是合并,而concatWith则是连接。不再详细示范。 -
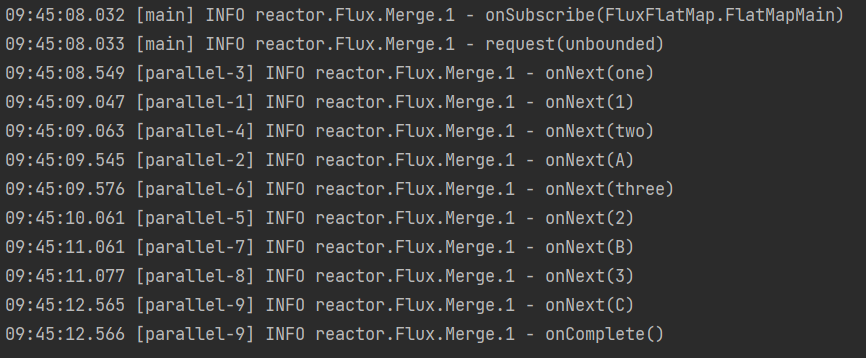
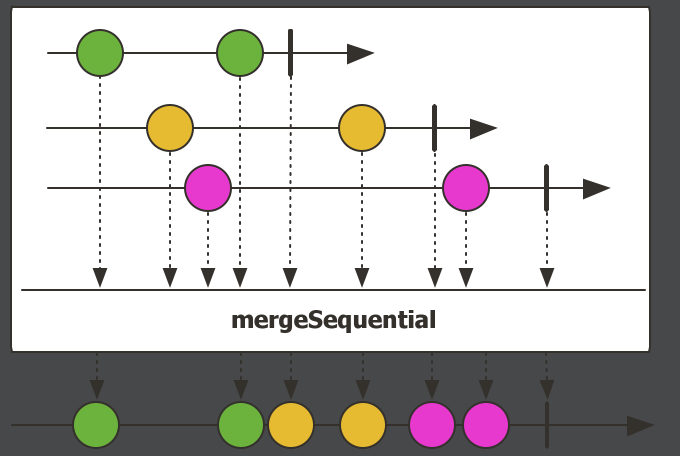
mergeSequential,按照流第一个到达的元素连接每个流。Flux.mergeSequential( Flux.just(1,2,3).delayElements(Duration.ofMillis(1000)), // 流1 Flux.just("A","B","C").delayElements(Duration.ofMillis(1500)), // 流2 Flux.just("one","two","three").delayElements(Duration.ofMillis(500)) //流3 ) .log() .subscribe();执行结果:
虽然是流3发布的速率快一点,但是是流1先到达的,所以得等流1的所有元素全部到达了,再开始组装第二个到达的流2,等流2的元素全部到达了之后,就开始组装最后到达的流3。需要注意的是,执行结果的出现顺序:
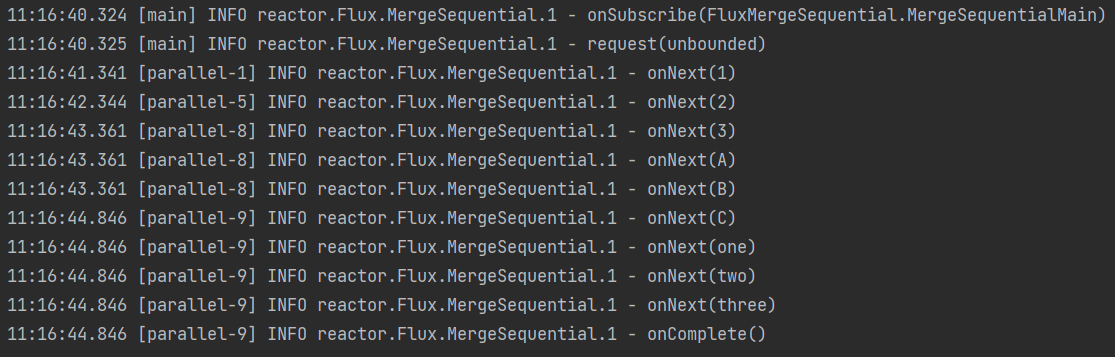
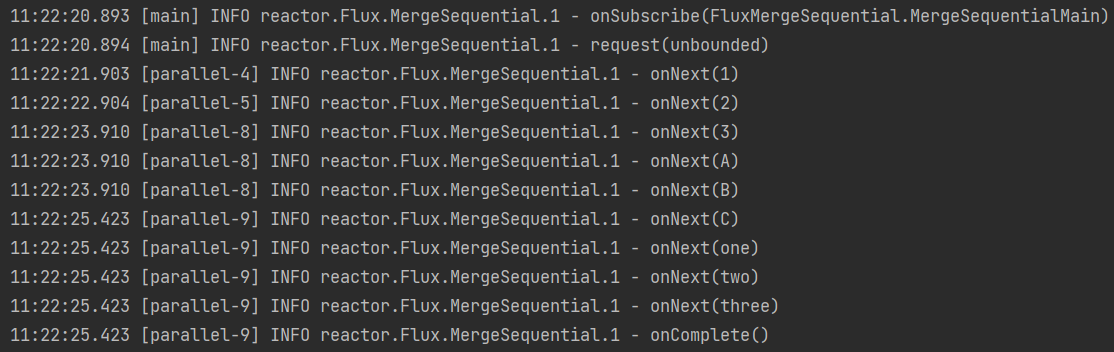
这是执行结果的顺序,因为流1是1秒发一个,所以
onNext(1)、onNext(2)都是一秒钟接受一个,到了onNext(3)的时候,流1结束了。同时流2的
onNext(A)、onNext(B)也发布完了,新流就会拼装流1和流2所发布完的元素。所以控制台上onNext(3)、onNext(A)、onNext(B)是同时出现的。到了
onNext(C)发布完,流2结束,同时流3也发布完成。所以onNext(C)、onNext(one)、onNext(two)、onNext(three)是同时出现的。从控制台日志出现的顺序可以看出,3个流其实是并发进行的,只不过是流1先到达的,所以要等流1的元素全部发布完了,再去组装下一个到达的流,以此类推,不管流里面的元素,每个流第一个元素到达的顺序,就是新流的连接顺序。




zip
-
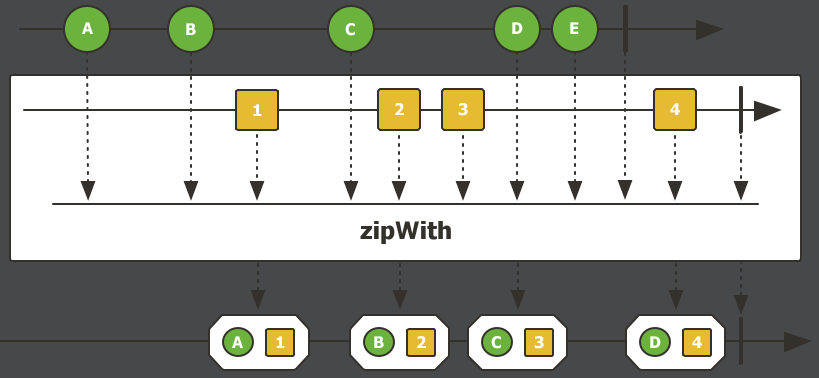
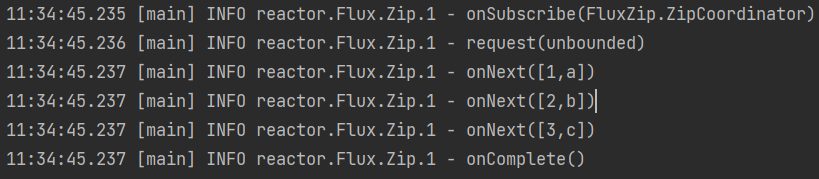
zipWith,压缩操作。会把两个流里的元素组成元组,形成一个新的流。如果有元素无法结对,则会被忽略。Flux.just(1,2,3) .zipWith(Flux.just("a","b","c","d")) .log() .subscribe();执行结果:
把原来的流里的
1和新流里的a,结成了元组[1,a],之后的也按顺序结合。而新流的元素d,没办法结对,没人跟他组成元组,所以他被忽略了。这里
zipWith的泛型是Tuple,也就是元组。有个很酷的操作,通过元组可以把两个流的元素结合起来变成一个新流。
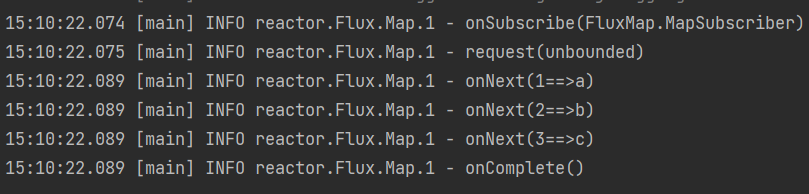
Flux.just(1,2,3) .zipWith(Flux.just("a","b","c","d")) .map(tuple -> { Integer t1 = tuple.getT1(); // 元组中的第一个元素 String t2 = tuple.getT2(); // 元组中的第二个元素 return t1 + "==>" + t2; }) .log() .subscribe();执行结果:
-
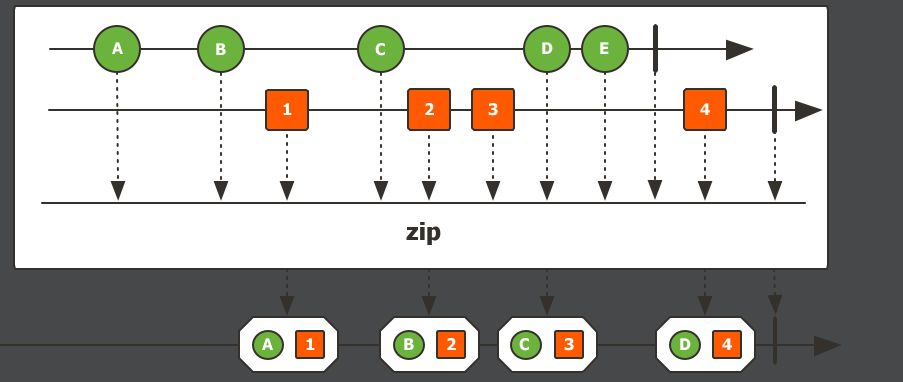
zip,多个流的压缩操作。会把最多8个流里的元素组成元组,形成一个新的流。如果有元素无法结对,则会被忽略。注意:最多只能压缩8个流。Flux.zip( Flux.just(1,2,3), Flux.just("a","b","c","d"), Flux.just("A","B") ) .log() .subscribe();执行结果:
跟
zipWith一样,只有能组成元组的元素才能压缩到新流里,没办法组成元组的会忽略掉。也能通过元组把多个流的元素结合起来变成一个新流。Flux.zip( Flux.just(1,2,3), Flux.just("a","b","c","d"), Flux.just("A","B") ) .map(tuple -> { Integer t1 = tuple.getT1(); String t2 = tuple.getT2(); String t3 = tuple.getT3(); return t1 + "==>" + t2 + "==>" + t3; }) .log() .subscribe();执行结果: