什么是响应式编码?
如果是用java.util.conccurrent.Flow提供的API来做订阅发布这类的编码成为响应式编程,以前的编码方式称为命令式编程。
Reactive Streams文档中说明了在JDK9中多了一个类java.util.concurrent.Flow,这个类是用来做响应式编程的基础

响应式宣言中则说明了什么样的系统才是响应式系统。
系统具备以下特质:即时响应性(Responsive)、回弹性(Resilient)、弹性(Elastic)以及消息驱动(Message Driven)。 我们称这样的系统为反应式系统(Reactive System)。
ReactiveStream是JVM面向流的库的标准和规范。这个库拥以下特点:
- 处理可能无限数量的元素
- 处理是有序的
- 在组件之间异步传递元素(流中的B元素不用等待A元素处理完)
- 强制性非阻塞背压模式
正压:数据的生产者给多少,消费者就要做多少
背压:消费者能做多少,就向生产者要多少
比如一个自来水管,
背压就是:我像喝多少水,我就打开水管接多少水
而正压是:自来水管中有多少水,我都得全部喝完,即使有一个大海的水我也得喝完
Tomcat中,如果一下子接收到1000w条数据,那么就得开1000w个线程来处理事情,生产者数据巨大,就会导致消费者压垮。这种模式称为正压。
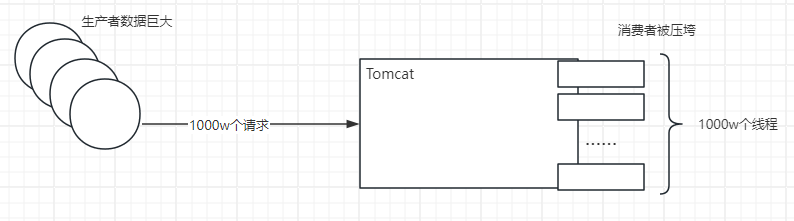
如果在请求与Tomcat中加一个缓冲队列,我把接收到的请求全部放在缓冲队列中。假如Tomcat部署在一个4核的服务器,就只开4个线程,那么就每个线程做完了任务再主动去缓冲队列领取一个任务,直至缓冲队列中的任务被领完。这样通过队列把任务缓存起来,由消费者根据自己的能力逐个处理。这种模式称为背压模式。

线程是越多越好还是越少越好呢?
结论:最理想的是:让少量线程一直忙,而不是让大量线程一直切换。所以线程数跟cpu核心数一样最好。
越多的核心只会产生激烈竞争。
如果有一个4核的cpu,有100个线程的话,平均一个核就会有25个线程在排队。线程就要切换,切换保留线程(浪费内存浪费时间)。
最理想的就是让每个核心只跑一个线程,跑完了这个线程,马上接下一个线程。这样一直跑,cpu不闲着。
还是上面的例子,
在线程数与cpu核心数一样的情况下,如果Tomcat中的某个线程需要查redis数据,等待返回,那么这个核心就会发生阻塞,这种情况该怎么办呢?
答案还是利用缓冲区。redis发送回来的数据会放在一个缓冲区中,而原来的线程则会放下原来的任务A,到缓冲队列中再领取一个任务B,先处理任务B,处理完了任务B,空闲了,再去缓冲区拿属于任务A的数据继续处理任务A。
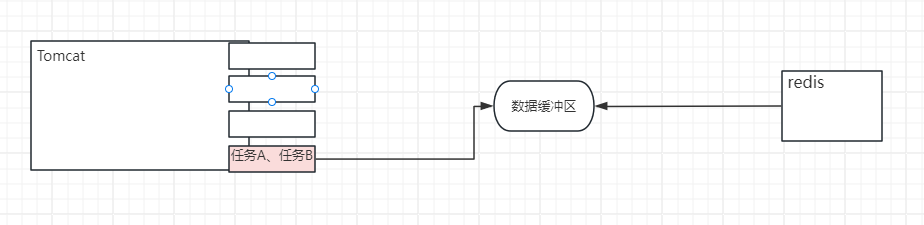
现在需要一个本地化的消息系统,让所有的异步线程能互相监听消息、处理消息,构建实时信息处理流。而Java中提供的ReactiveStream这套方案就能帮助做这个事情。
非阻塞编码与阻塞编码的区别
通过一个demo可以理清楚阻塞与非阻塞的关系。说明:这个demo没有任何意义,只是为了从代码层面理清楚阻塞与非阻塞的关系。
public class ReactiveStream {
public void A (){
Date startTime = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
String start = sdf.format(startTime);
System.out.println("A开始时间:" + start);
B("A的数据");
System.out.println("A做完事----------------------------------------------");
Date endTime = new Date();
String end = sdf.format(endTime);
System.out.println("A结束时间:" + end);
}
public void B (String arg){
System.out.println("**********************************B做事,输出:" + arg);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
ReactiveStream reactiveStream = new ReactiveStream();
System.out.println("111111");
reactiveStream.A ();
System.out.println("222222");
}
}
当执行main的时候,会调用A()方法,而A()方法中又调用了B()方法。所以一旦B()方法阻塞,整个A()方法就会被阻塞。
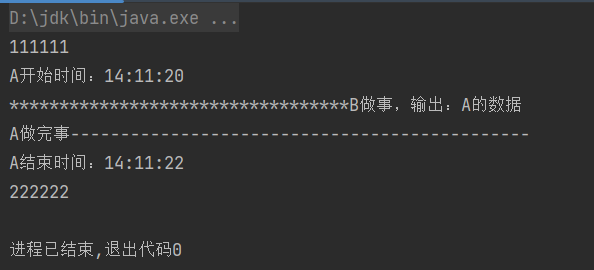
如果这时加一个缓冲区,让A()方法不用等待B()方法,谁也不等谁会是什么结果呢。
public class ReactiveStream {
public void A (){
Date startTime = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
String start = sdf.format(startTime);
System.out.println("A开始时间:" + start);
String a = "A的数据";
System.out.println("A做完事----------------------------------------------");
buffer[0] = a;
Date endTime = new Date();
String end = sdf.format(endTime);
System.out.println("A结束时间:" + end);
}
public void B (){
String arg = buffer[0];
System.out.println("**********************************B做事,输出:" + arg);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
private static String[] buffer = new String[1];
public static void main(String[] args) {
ReactiveStream reactiveStream = new ReactiveStream();
System.out.println("111111");
reactiveStream.A ();
reactiveStream.B();
System.out.println("222222");
}
}
输出结果:
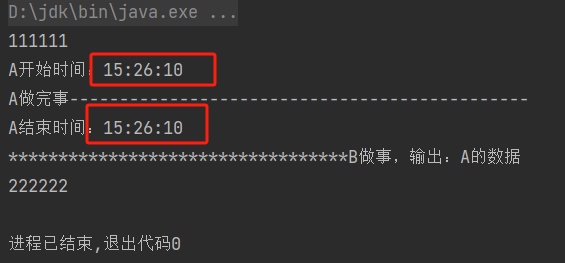
A()方法不用等待B()方法的返回,A把数据放到buffer数组里面,当B需要的时候再去数组里拿。如果B不拿的话,这个数组或者说A产生的数据是没有任何意义的。A只是提供一个数据,并没有其他的作用,而提供数据还要等B给返回结果,就会浪费掉时间。所以A把数据放在了缓冲区buffer里,就完成了它的使命,就可以完结了。而当B需要运行的时候,自己去缓冲区拿数据,能处理多少拿多少。什么时候去拿数据,拿多少数据完全是B自己决定的。
但是这里有一个问题,reactiveStream.B();还是会阻塞System.out.println("222222");,为了解决这个问题,则可以异步执行reactiveStream.B();
public static void main(String[] args) {
ReactiveStream reactiveStream = new ReactiveStream();
System.out.println("111111");
reactiveStream.A ();
new Thread(()->{
reactiveStream.B();
}).start();
System.out.println("222222");
}
输出结果:
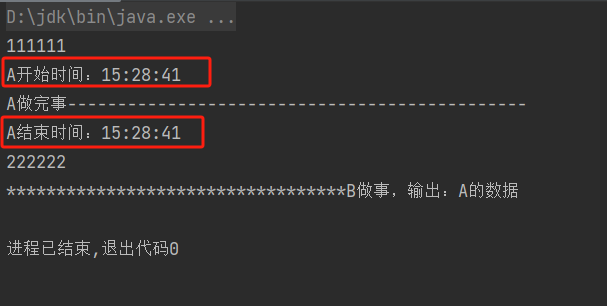
这样一来,A不等待B,System.out.println("222222");也不会等待reactiveStream.B();。互相之间都不等待,互相不阻塞。
总结:引入一个缓存区,引入消息队列,就能实现全系统、全异步、不阻塞、不等待、实时响应。
命令式编程与响应式编程的区别
以前的编程模型(命令式编程)在干什么?怎么编码?编码的时候注意什么问题?
function a(String arg[]){
// 业务处理
// 数据返回
}
命令式编程:(全自定义)
- 给他什么样的数据 (传参)
- 怎么处理数据 (业务)
- 处理后返回结果 (结果)
自己定义参数、业务、和返回
响应式/声明式编程:
万物皆是数据处理:数据结构+算法=程序
- 一个数据/一堆数据(传参)
- 流操作(业务)
- 新数据/新流(结果)
得到一个流之后,只需说清楚要对这个流怎么操作,最终会产生一个什么结果数据
例如:
List<String> reList;
reList.add("张三");
reList.add("皮蛋侠");
reList.add("李四");
命令式编程:
for(String a : reList){
// 一系列操作
}
响应式编程:
List<String> newList = reList.stream().filter(s -> !s.equals("皮蛋侠")).collect(Collectors.toList());
在命令式编程中,需要自定义for循环,要定义for循环什么时候开始、什么时候结束、for循环的顺序、for循环里面的一系列操作等等,都需要自己定义。
而响应式编程中,我拿到了一个流reList,我过滤出流里面值不为"皮蛋侠"的所有元素,并且收集到一个新的流newList里面。
相较于传统命令式编程,我只需明确我要对这个流数据做什么,拿到什么结果就可以了。至于怎么遍历、怎么处理、什么时候处理到第二个元素等等一系列我都不用关心。数据是自流动的,而不是靠迭代被动流动的。
推拉模型:迭代器(拉模型)、流模式(推模型)
迭代器要自己一个一个拉取,比如for循环for(String a : reList),需要自己在reList里面拿元素。
流是推模式,只要上游reList有数据,里面的数据就会顺着流水线管道一个一个的自动推下来了,什么都不用管。
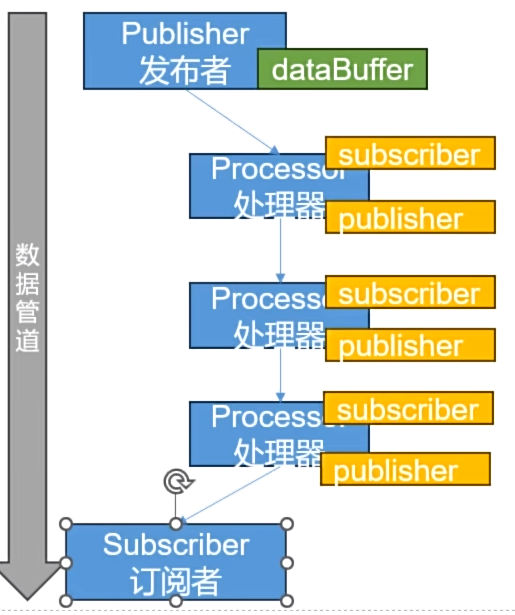
发布者负责流的源头,发布者默认把数据发布到他的缓冲区临时存起来,知道有一个订阅者对这个数据感兴趣。
但是订阅者不想要源数据,而是要把源数据经过一系列的处理,才变成订阅者想要的数据。
所以要在中间加一系列的处理器,而处理器本身即是发布者,也是订阅者,订阅上层的数据,把数据处理完后又要发布数据给下一层。处理器相当于StreamAPI的中间操作。
reactive stream规范核心接口:
在Java9的Reactive Stream里提供了几大组件,也是reactive stream规范核心接口
- Publisher:发布者;生产数据流
-
Subscriber:订阅者;消费数据流
-
Subscription:订阅关系
订阅关系是发布者和订阅者之间的关键接口。订阅者通过订阅来表示对发布者产生的数据的兴趣。订阅者可以请求一定数量的元素,也可以取消订阅。
-
Processor:处理器;
处理器是同时实现了发布者和订阅者接口的组件。它可以接受来自一个发布者的数据,进行处理,并将结果发布给下一个订阅者。处理器在Reactor中充当中间环节,代表一个处理阶段。允许你在数据流中进行转换、过滤和其他操作。
reactive stream规范发布数据与订阅数据
先给完整代码:
public class FlowDemo {
public static void main(String[] args) throws InterruptedException {
// 1. 定义一个发布者,发布数据
SubmissionPublisher<String> publisher = new SubmissionPublisher<>();
// 2. 定义一个订阅者,订阅发布者发布的数据
Flow.Subscriber<String> subscriber = new Flow.Subscriber<String>() {
private Flow.Subscription subscription; // 订阅者订阅发布者的时候,会得到一个订阅对象
@Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了");
this.subscription = subscription;
// 从上游请求一个数据
subscription.request(1);
}
@Override // 在下一个元素到达时,执行这个回调
public void onNext(String item) {
System.out.println(Thread.currentThread() + "订阅者接收到数据:" + item);
subscription.request(1);
}
@Override // 在错误发生时
public void onError(Throwable throwable) {
System.out.println(Thread.currentThread() + "订阅者接收到错误:" + throwable);
}
@Override // 在完成时
public void onComplete() {
System.out.println(Thread.currentThread() + "订阅者接收到完成信号");
}
};
// 3. 订阅发布者--绑定发布者和订阅者
publisher.subscribe(subscriber);
// 发布10条数据
for (int i = 0; i < 10; i++){
publisher.submit("p-" + i);
// publisher发布的所有数据在他的buffer区
}
publisher.close(); // 关闭发布者
Thread.sleep(1000000); // 防止主线程太快跑完,先阻塞一下
}
}
代码运行输出:
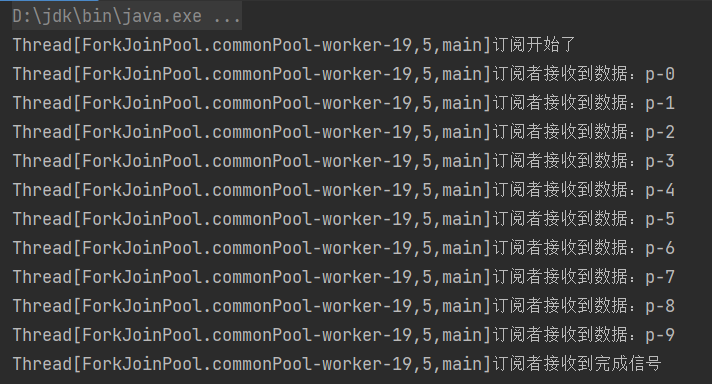
实现一个响应式系统的Demo,需要有三个最基本的东西:消费者、订阅者、订阅关系。
- 定义一个发布者,发布数据
// 1. 定义一个发布者,发布数据 SubmissionPublisher<String> publisher = new SubmissionPublisher<>(); - 定义一个订阅者,订阅发布者发布的数据
定义订阅者需要重写内部的几个方法:
onSubscribe:在订阅时,执行这个回调
onNext:在下一个元素到达时,执行这个回调
onError:在错误发生时,执行这个回调
onComplete:在完成时,执行这个回调
// 2. 定义一个订阅者,订阅发布者发布的数据 Flow.Subscriber<String> subscriber = new Flow.Subscriber<String>() { private Flow.Subscription subscription; // 订阅者订阅发布者的时候,会得到一个订阅对象 @Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调 public void onSubscribe(Flow.Subscription subscription) { System.out.println(Thread.currentThread() + "订阅开始了"); this.subscription = subscription; // 从上游请求一个数据 subscription.request(1); } @Override // 在下一个元素到达时,执行这个回调 public void onNext(String item) { System.out.println(Thread.currentThread() + "订阅者接收到数据:" + item); subscription.request(1); } @Override // 在错误发生时 public void onError(Throwable throwable) { System.out.println(Thread.currentThread() + "订阅者接收到错误:" + throwable); } @Override // 在完成时 public void onComplete() { System.out.println(Thread.currentThread() + "订阅者接收到完成信号"); } };这里有必要提一下
onSubscribe、onNext这两个方法。@Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调 public void onSubscribe(Flow.Subscription subscription) { System.out.println(Thread.currentThread() + "订阅开始了"); this.subscription = subscription; // 从上游请求一个数据 subscription.request(1); } @Override // 在下一个元素到达时,执行这个回调 public void onNext(String item) { System.out.println(Thread.currentThread() + "订阅者接收到数据:" + item); subscription.request(1); }订阅了一个发布者之后,就会进入到这个方法里面。而这两个方法里的
subscription.request(1);,代表从流中请求一个元素。这里先提一嘴,到稍后再细说。 -
订阅发布者–绑定发布者和订阅者
// 3. 订阅发布者--绑定发布者和订阅者 publisher.subscribe(subscriber); - 发布10条数据
注意!必须得绑定关系之后再发布数据,订阅者才能成功订阅到数据
// 发布10条数据 for (int i = 0; i < 10; i++){ publisher.submit("p-" + i); // publisher发布的所有数据在他的buffer区 }在使用 Java Flow API 中的
SubmissionPublisher和Subscriber时,确保先建立订阅关系再发布数据是为了避免数据丢失或混乱的情况。当先发布数据而没有建立订阅关系时,数据可能会丢失,因为没有订阅者来接收这些数据。订阅者在订阅之前,发布者就开始发布数据,这会导致数据流失。
通过先建立订阅关系再发布数据,可以确保数据不会丢失,因为一旦订阅关系建立,订阅者就可以立即开始接收发布者发送的数据。这样可以保证数据的完整性和一致性,避免数据丢失或混乱。
-
当执行完
publisher.close(); // 关闭发布者这行代码之后,就会进入到onComplete方法里面,完成相应操作。
onSubscribe与onNext
可以看到onSubscribe方法跟onNext方法中都有条语句:subscription.request(1); // 从上游请求一个数据。
这行代码的意思是要请求一个数据,如果onSubscribe方法中将这条代码抹去,则
@Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了");
this.subscription = subscription;
// 从上游请求一个数据
// subscription.request(1);
}
执行结果:
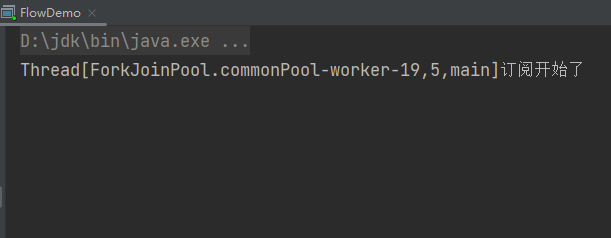
可以看到只进行了订阅,并没有拿到订阅的数据。由此得知,onSubscribe方法跟onNext方法中的subscription.request(1);构成了一个动态平衡。
订阅开始后,请求一条数据。onNext方法消费完这条数据后,再请求一条数据。这样数据就会源源不断的流进来消费掉,直至数据消费完为止。
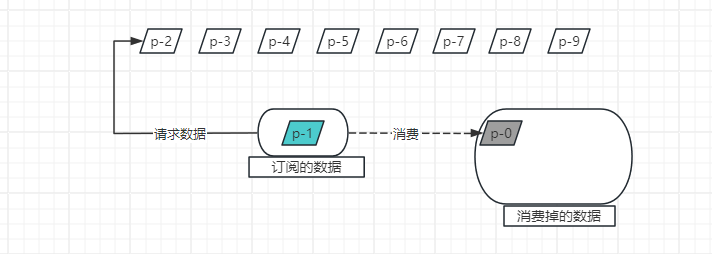
相反,如果只有onSubscribe方法请求了数据,onNext方法中不请求数据会是什么结果呢?
@Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了");
this.subscription = subscription;
// 从上游请求5个数据
subscription.request(5);
}
@Override // 在下一个元素到达时,执行这个回调
public void onNext(String item) {
System.out.println(Thread.currentThread() + "订阅者接收到数据:" + item);
// subscription.request(1);
}
执行结果:
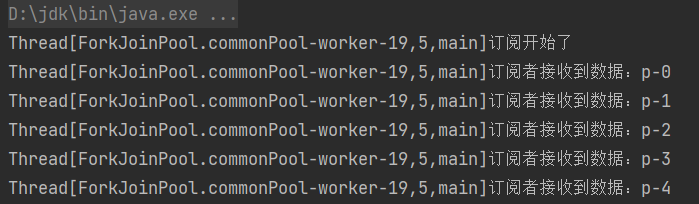
可以看到在订阅开始的时候请求了5个数据,而onNext方法把这些数据消费完之后就没有请求新的数据了,所以程序接收完p-4之后就停止了。
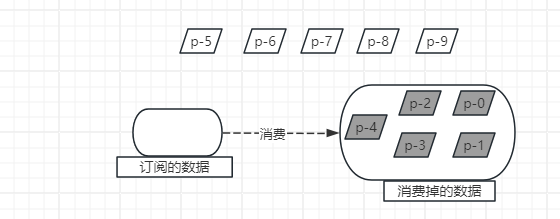
由此可得,通过onSubscribe方法跟onNext方法就能控制流的消耗速度。
例如:
比如我能消费5条数据,但是消费完3条数据之后我休息一秒后才能继续消费2条数据,再多就不行了。
这个需求怎么实现呢?
方法一:
- 订阅的时候请求3条数据
- 消费完3条数据之后休息一秒再请求2条数据
@Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了");
this.subscription = subscription;
// 从上游请求三个数据
subscription.request(3);
}
int count = 0;
@Override // 在下一个元素到达时,执行这个回调
public void onNext(String item) {
System.out.println(Thread.currentThread() + "订阅者接收到数据:" + item);
count ++ ;
if (count == 3){
try {
Thread.sleep(1000);
System.out.println("--------------休息了一秒--------------");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
subscription.request(2); // 休息完之后再请求两条数据
}
}
执行结果:
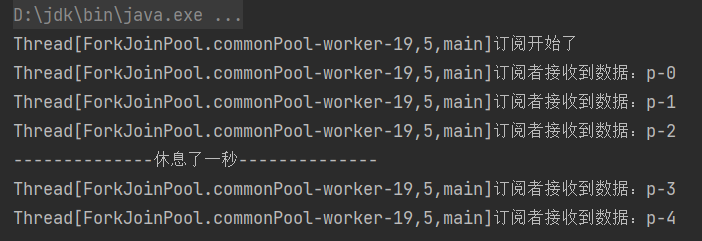
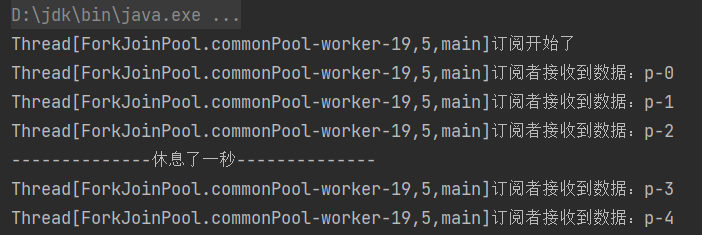
方法二:
方法一是在订阅的时候就请求了3条数据,当消费完第三条的数据的时候,休息一秒,再向上游请求2条数据。
除了这种方法,还可以在订阅的时候直接请求5条数据,当消费完第三条数据的时候,休息一秒再继续消费,消费完之后就不再请求数据了
@Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了");
this.subscription = subscription;
// 从上游请求一个数据
subscription.request(5);
}
int count = 0;
@Override // 在下一个元素到达时,执行这个回调
public void onNext(String item) {
System.out.println(Thread.currentThread() + "订阅者接收到数据:" + item);
count ++ ;
if (count == 3){
try {
Thread.sleep(1000);
System.out.println("--------------休息了一秒--------------");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
执行结果:
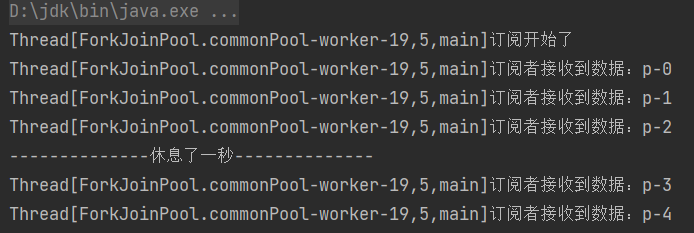
方法三:
除了以上两种方法,还可以通过一个动态平衡的流来接收获取数据,消费完第3个数据之后就休息一秒,接着消费剩下的数据,当消费完第5个数据的时候,取消订阅。
@Override // 在订阅时 onXxxx:在xxx事件发生时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了");
this.subscription = subscription;
// 从上游请求一个数据
subscription.request(1);
}
int count = 0;
@Override // 在下一个元素到达时,执行这个回调
public void onNext(String item) {
System.out.println(Thread.currentThread() + "订阅者接收到数据:" + item);
count ++ ;
if (count == 3){
try {
Thread.sleep(1000);
System.out.println("--------------休息了一秒--------------");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
subscription.request(1);
if (count == 5){
subscription.cancel();
}
}
执行结果:
以上三种方法执行过程不一样,但是得到的结果却是一样的。
还能同时多个订阅者同时订阅同数据。
在上面基础,再加一个订阅者:subscriber2,然后绑定关系。
……
Flow.Subscriber<String> subscriber2 = new Flow.Subscriber<String>() {
private Flow.Subscription subscription; // 订阅者订阅发布者的时候,会得到一个订阅对象
@Override
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + ">>>>>>订阅开始了");
this.subscription = subscription;
// 从上游请求一个数据
subscription.request(1);
}
@Override
public void onNext(String item) {
System.out.println(Thread.currentThread() + ">>>>>>订阅者接收到数据:" + item);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
System.out.println(Thread.currentThread() + ">>>>>>订阅者接收到错误:" + throwable);
}
@Override
public void onComplete() {
System.out.println(Thread.currentThread() + ">>>>>>订阅者接收到完成信号");
}
};
// 3. 订阅发布者--绑定发布者和订阅者
publisher.subscribe(subscriber);
publisher.subscribe(subscriber2);
……
执行结果:
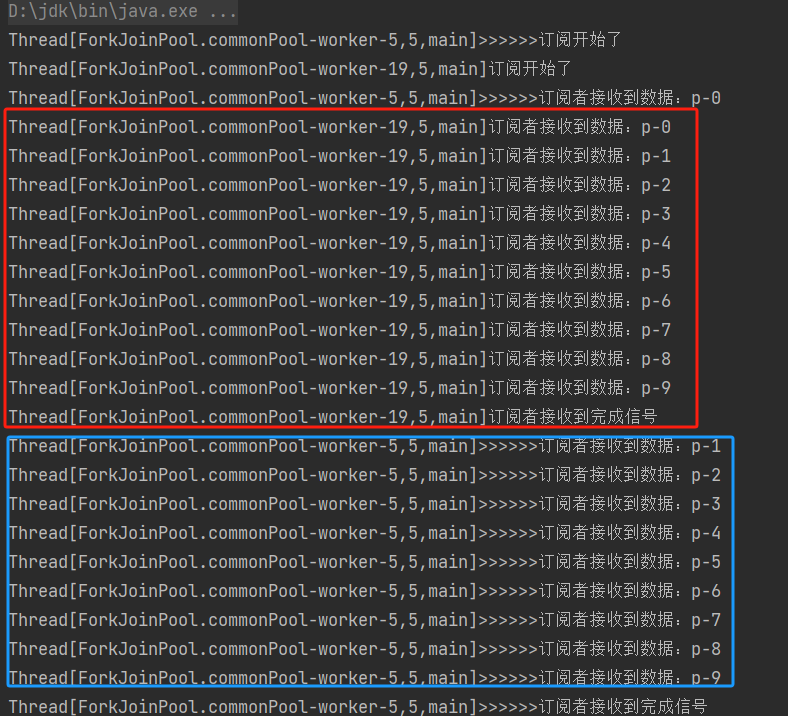
可以看到两个线程各做各的事情,并且对数据的处理速度也可以是不一样的。
并且可以看到这两个线程都是ForkJoinPool线程池中的线程,并非主线程。那么主线程在哪里呢?
主线程负责发布数据,在发布数据中打印一下线程:
// 发布10条数据
for (int i = 0; i < 10; i++){
publisher.submit("p-" + i);
System.out.println(Thread.currentThread() + "发布者发布数据:" + i);
// publisher发布的所有数据在他的buffer区
}
执行结果:
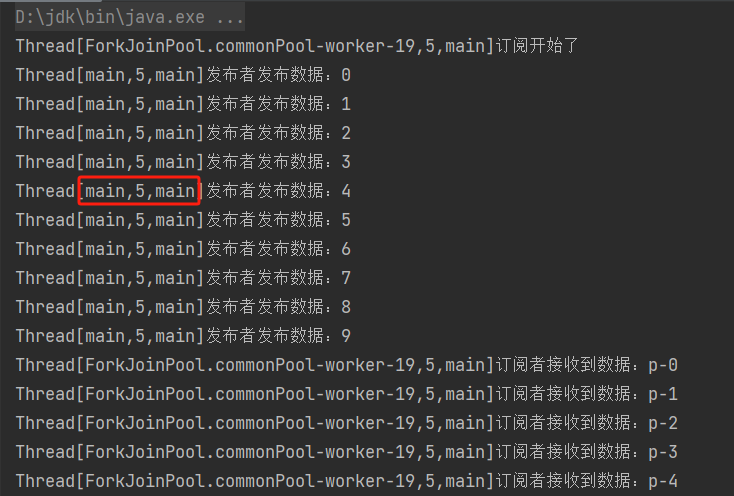
可以看到,主线程负责发布数据,而ForkJoinPool线程池中的其他线程则负责订阅数据。jvm底层已经对整个发布订阅做好了异步、线程池、消息缓冲区。
reactive stream处理器组件
之前提到过reactive stream AIP有Publisher发布者、Subscriber订阅者、Subscription订阅关系、Processor处理器;上面只演示了前三个,只是发布数据,订阅者拿到数据并且打印出来。而实际我们需要拿到源数据之后进行一系列的加工,从而拿到一些经过组装好的流水线加工完成的数据。
这就用到了Processor处理器。一条完整的流水线应该是这样的:发布者-->(处理器)*n-->订阅者。发布者发布数据之后,经过n个处理器的加工,得到有用的数据给到订阅者。
Processor处理器即是发布着也是订阅者。根据上面的流水线流程,可以得到一条责任链:第一个处理器订阅发布者的数据,订阅者订阅最后一个处理器的数据。
这样就组成了一条完整的数据管道。也就是前面提到的这个图:
先给完整代码:
public class FlowDemo {
// 定义中间操作处理器,继承了发布者的接口,只需要实现订阅者接口
static class MyProcessor extends SubmissionPublisher<String> implements Flow.Processor<String,String>{
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
System.out.println("Processor订阅开始了--------");
this.subscription = subscription;
// 从上游请求一个数据
subscription.request(1);
}
@Override
public void onNext(String item) {
System.out.println("Processor拿到数据:" + item);
item += " 加工的数据"; // 加工数据
submit(item); // 加工后将数据发布出去
subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
System.out.println("Processor接收到错误:" + throwable);
}
@Override
public void onComplete() {
System.out.println("Processor接收到完成信号--------");
}
}
public static void main(String[] args) throws InterruptedException {
// 定义一个发布者,发布数据
SubmissionPublisher<String> publisher = new SubmissionPublisher<>();
// 定义一个订阅者,订阅发布者发布的数据
……
// 定义中间操作,对源数据进行加工
MyProcessor myProcessor = new MyProcessor();
// 绑定责任链
publisher.subscribe(myProcessor);
myProcessor.subscribe(subscriber);
// 发布10条数据
for(……){……}
publisher.close(); // 关闭发布者
Thread.sleep(1000000); // 防止主线程太快跑完,先阻塞一下
}
}
代码中,定义了一个中间操作处理器MyProcessor,因为Processor即使发布者也是订阅者,所以为了省事就直接继承了SubmissionPublisher<String>,MyProcessor中也需要实现订阅者的方法。
与订阅者方法不同的是,在MyProcessor中的onNext里对数据进行加工:加了后缀“ 加工的数据”,加工完了之后把加工好的数据发布出去。
👉原来的subscriber订阅publisher,现在因为Processor的出现,要加一层中间商:
// 绑定责任链
publisher.subscribe(myProcessor);
myProcessor.subscribe(subscriber);
myProcessor订阅publisher—> subscriber订阅myProcessor,最终subscriber拿到了经过myProcessor加工处理后的数据
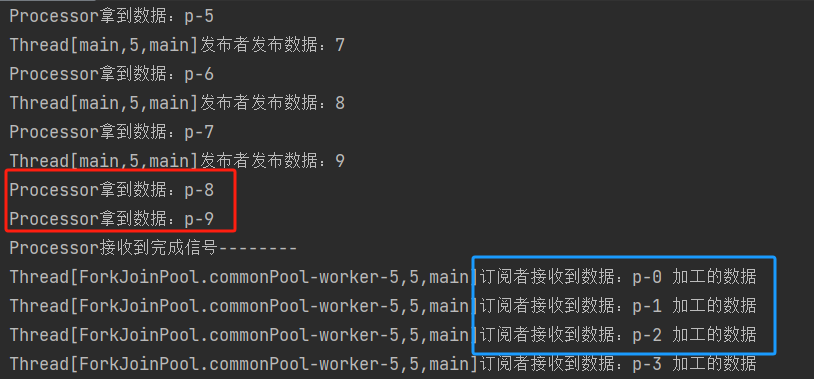
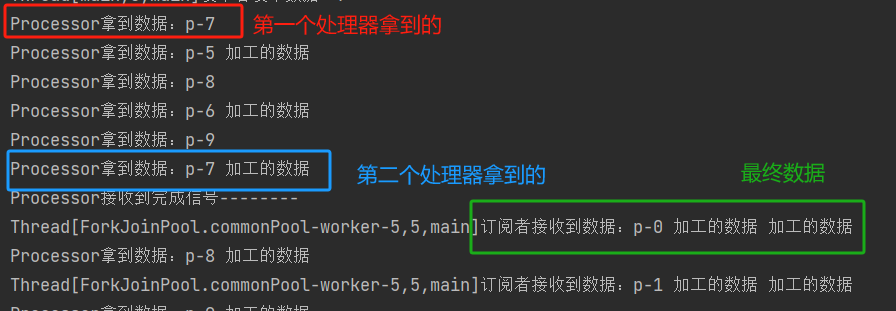
如果有多个处理器,就有多个中间商,为了方便我用同一个处理器进行多次加工:
// 定义中间操作,对源数据进行加工
MyProcessor myProcessor = new MyProcessor();
MyProcessor myProcessor1 = new MyProcessor();
// 绑定数据链
publisher.subscribe(myProcessor);
myProcessor.subscribe(myProcessor1);
myProcessor1.subscribe(subscriber);
输出结果: