响应式编程总结:
- 底层:基于数据缓冲队列 + 消息驱动模型 + 异步回调机制(事件驱动)
- 编码:流式编程 + 链式调用 + 声明式API
- 效果:优雅全异步 + 消息实时处理 + 高吞吐量 + 占用少量资源
响应式编程准备
在reactor文档中看一下如何使用Reactor框架。
- 第一步,先导入依赖
<dependencyManagement> <dependencies> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-bom</artifactId> <version>2023.0.6</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-core</artifactId> </dependency> <dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-test</artifactId> <scope>test</scope> </dependency> </dependencies>
事件感知API
链式API中,下面的操作符,操作的是上面的流
当流发生什么事的时候,触发一个回调,系统调用提前定义好的钩子函数(Hook,钩子函数)。doOnXxx
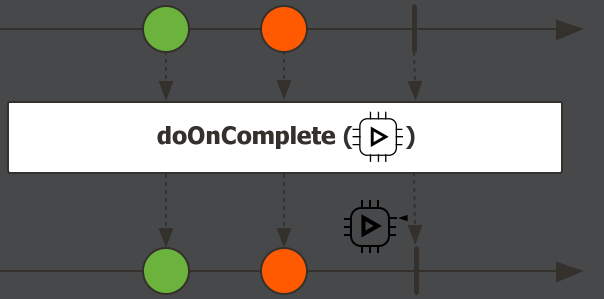
doOnComplete,在流成功完成时触发

Flux<Integer> flux = Flux.just(1, 2, 3).doOnComplete(()-> System.out.println("流已结束")); flux.subscribe(System.out::println);输出结果:
-
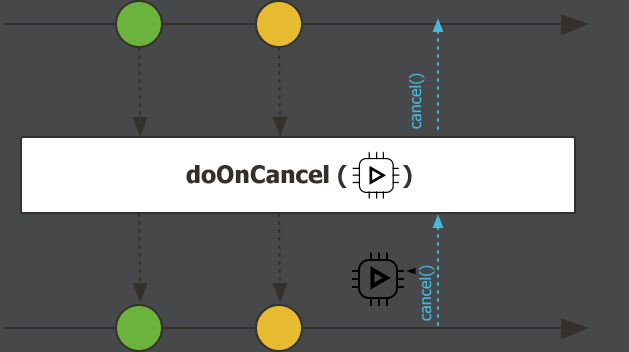
doOnCancel,流被取消时触发
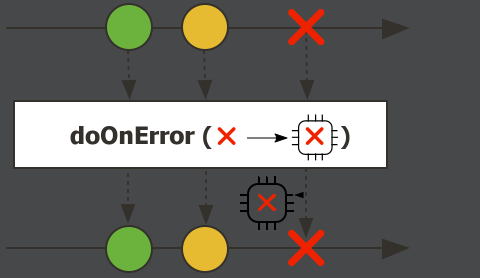
.doOnCancel(()-> System.out.println("流已取消")) doOnError,流出错时触发
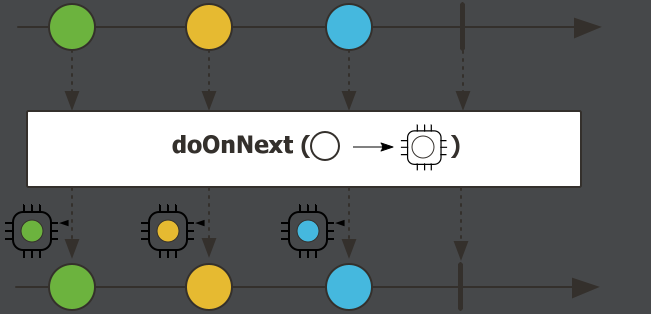
.doOnError(throwable -> System.out.println("流出错"))doOnNext,流的每个元素(流的数据)到达时触发
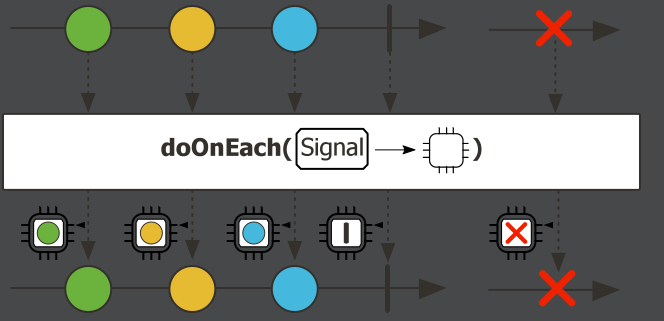
.doOnNext(integer -> System.out.println("处理数据" + integer))doOnEach,流的每个元素(流的数据和信号)到达的时候触发
.doOnEach(integerSignal -> System.out.println("处理数据" + integerSignal))针对流中的每个信号(元素、错误信号或完成信号)的操作。这意味着它在每个元素、错误或完成信号发出时都会执行指定的操作。
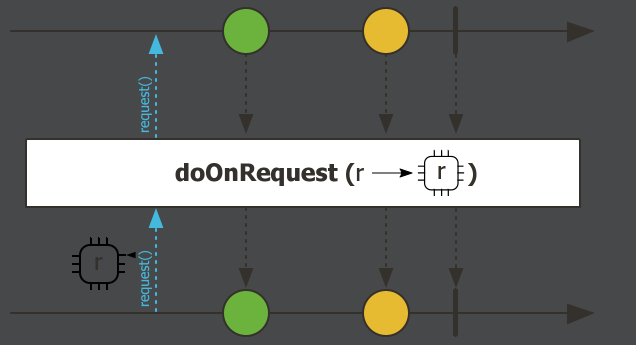
.doOnRequest,消费者请求流元素的时候触发
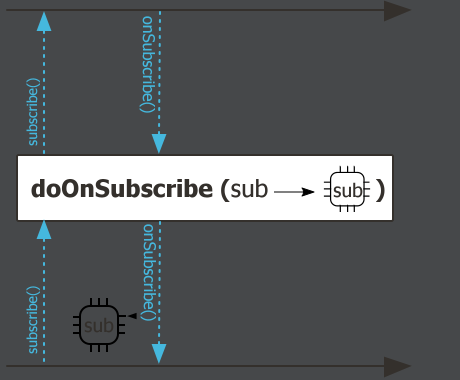
.doOnRequest(integer -> System.out.println("请求数据" + integer))doOnSubscribe,流被订阅的时候触发
.doOnSubscribe(subscription -> System.out.println("订阅流" + subscription))doOnDiscard,流被忽略的时候触发.doOnDiscard(Object.class, integer -> System.out.println("丢弃数据" + integer))

响应式流日志
.log()方法可以把流的过程打印出来,但是位置不同,记录的流也不同。
比如:
Flux.range(1,5) // 初始流
.log()
.filter(i -> i>3) // 新流1
.map(i -> "前缀" + i) // 新流2
.subscribe(System.out::println);
这段代码的执行顺序是:
- 有一个元素为1~5的初始流,打印这个初始流日志
- 过滤初始流中大于3的元素,组成新流1
- 把新流1中的元素加上
"前缀",形成新流2 - 订阅新流2并输出新流2中的元素
执行结果:
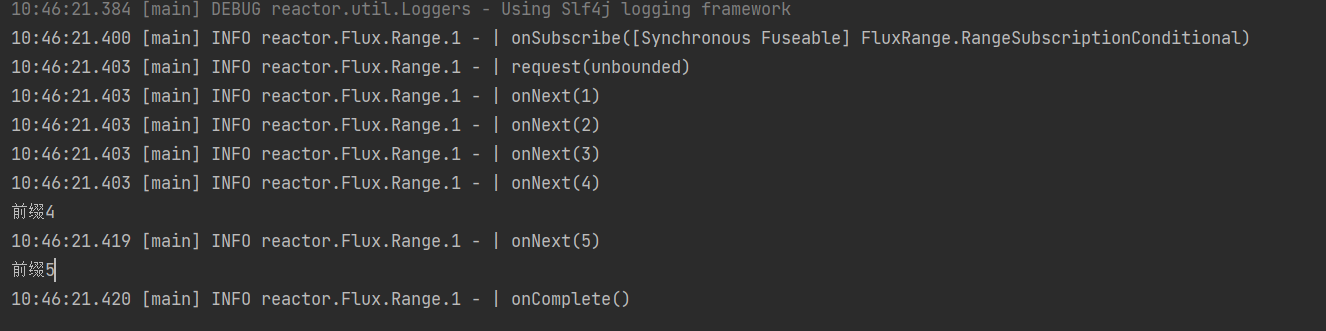
所以这个log()日志记录的是原始流的完整流程。从订阅onSubscribe到请求元素request再到元素到达onNext最后订阅结束onComplete。其中onNext方法执行了5次。证明记录的是初始流。
如果把log()的位置换到下面:
Flux.range(1,5)
.filter(i -> i>3)
.log()
.map(i -> "前缀" + i)
.subscribe(System.out::println);
执行结果:

这里的日志onNext方法记录的就是4和5,也就是新流1的完整流程。
请求重塑buffer缓冲
Flux.range(1,5)
.buffer(3)
.log()
.subscribe(System.out::println);
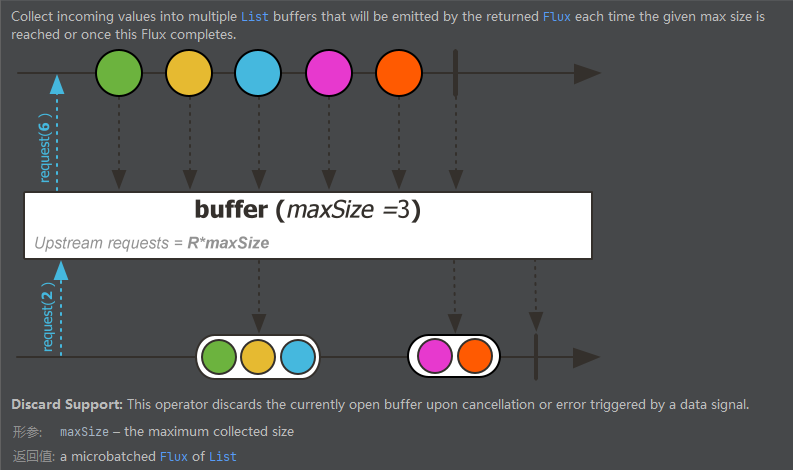
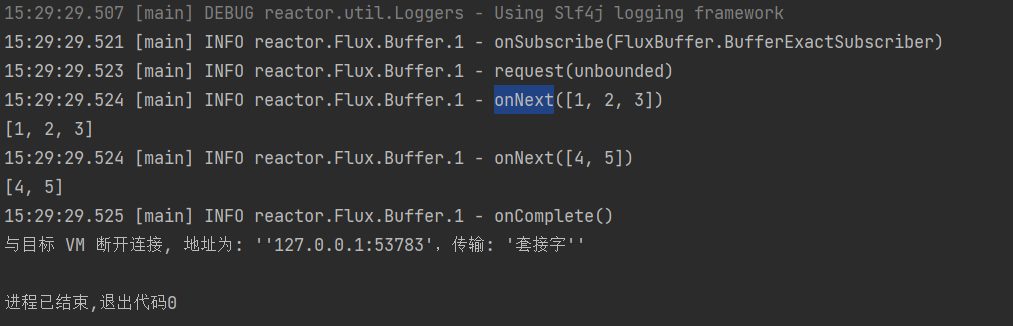
有一个元素为1~5的流,缓冲区空间为3个元素,装满3个元素后再一起发给消费者,如果到最后只剩2个元素了,不满3个元素,那就把剩下的2个元素一起发给消费者。通过日志可以看到:onNext方法只被调用了两次,说明只收到了两次元素。
这时候,如果消费者这时候request(1)请求一次数据,那么收到的将会是[1, 2, 3],这一次数据是3个元素。
请求重塑limitRate限流
Flux.range(1,5)
.log()
.limitRate(2)
.subscribe();
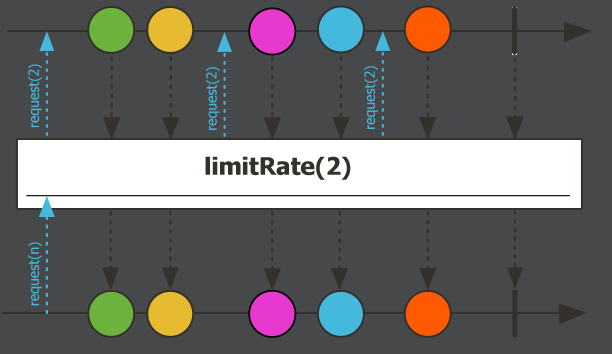
限流操作,每次向上游请求多少个元素。但是这里有一个阈值,是一个75%的预取策略。如果75%的元素已经处理了,继续请求新的75%的元素。
比如
.limitRate(100)第一次请求100个数据,如果75个元素已经处理了,继续请求新的75个元素。
创建序列generate-同步环境
以编程方式创建自定义序列。编程时有可能有一些序列不是通过Flux、Mono这些API简单创建出来的,而是需要经过一系列的代码操作。这个时候,同步环境下可以用generate。Flux和Mono都有这个方法。
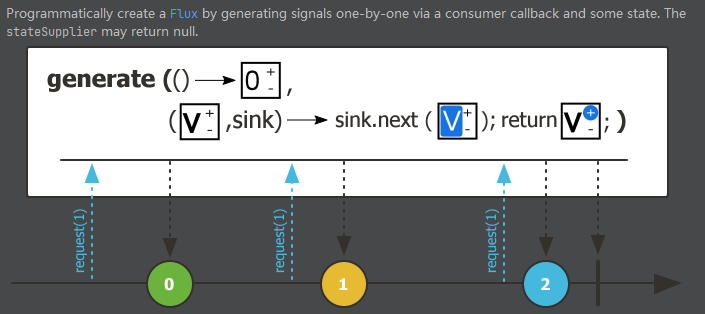
Sink是流通道,如果往流通道里塞一个元素,也代表着流里面有一个元素了。调用.next方法,就代表往通道里放了一个元素。
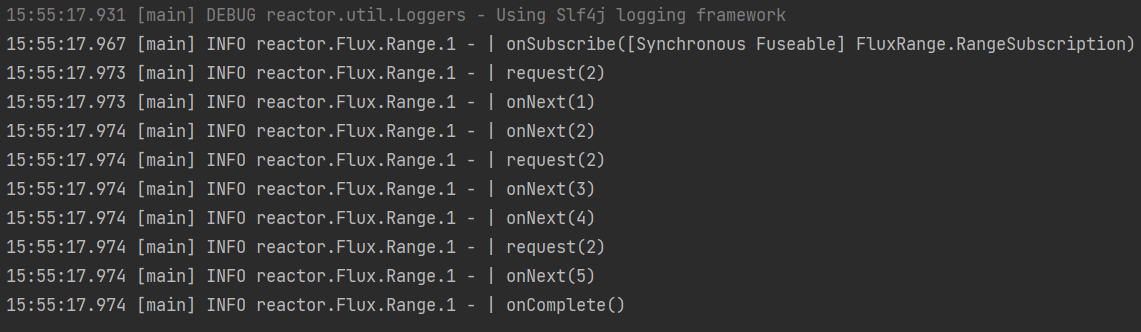
Flux.generate(() -> 0, // 初始state值
(state, sink) -> {
if (state <= 10) {
if (state == 7){
sink.next(state + 70);
}else {
sink.next("元素: " + state); // 把元素传出去
}
}else {
sink.complete(); // 完成信号
}
return state + 1;
})
.log()
.subscribe();
执行结果:
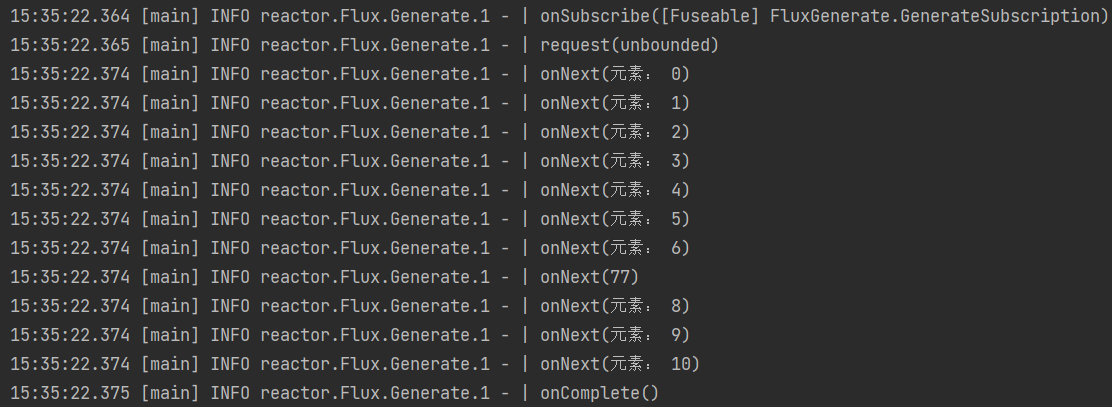
这就是自定义的序列,在元素为7时换成77。
创建序列create-多线程
同步环境下可以用generate,异步多线程的情况下就用create。
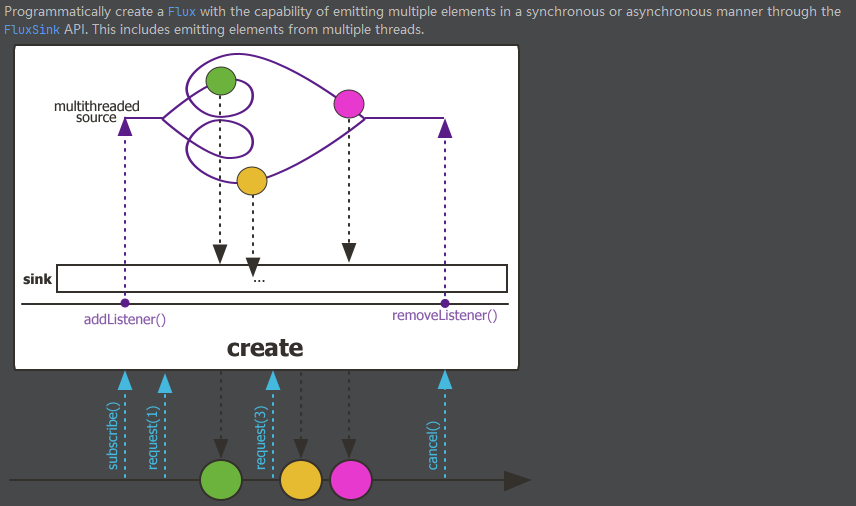
Flux.create(fluxSink -> {
for (int i = 0; i <= 10; i++ ){
fluxSink.next(i);
}
})
.log()
.subscribe();
执行结果:
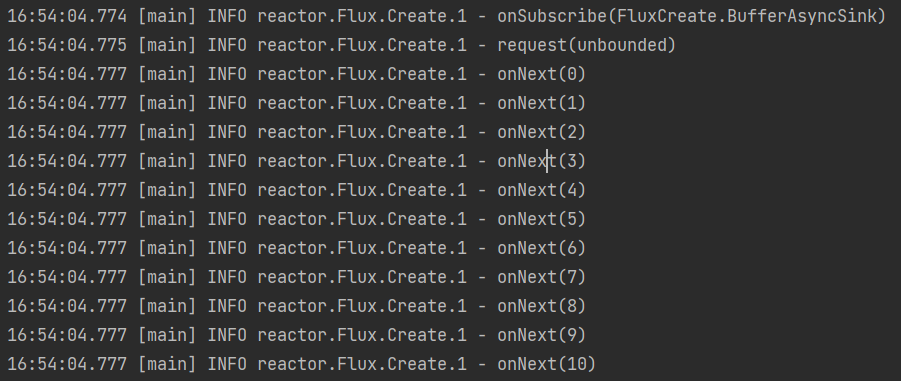
自定义元素处理handle
handle可以自定义处理流中元素处理规则。
Flux.range(1,5)
.handle((value, sink)->{
System.out.println("拿到的值:" + value);
sink.next("自定义处理结果:P" + value);
})
.log()
.subscribe();
执行结果:
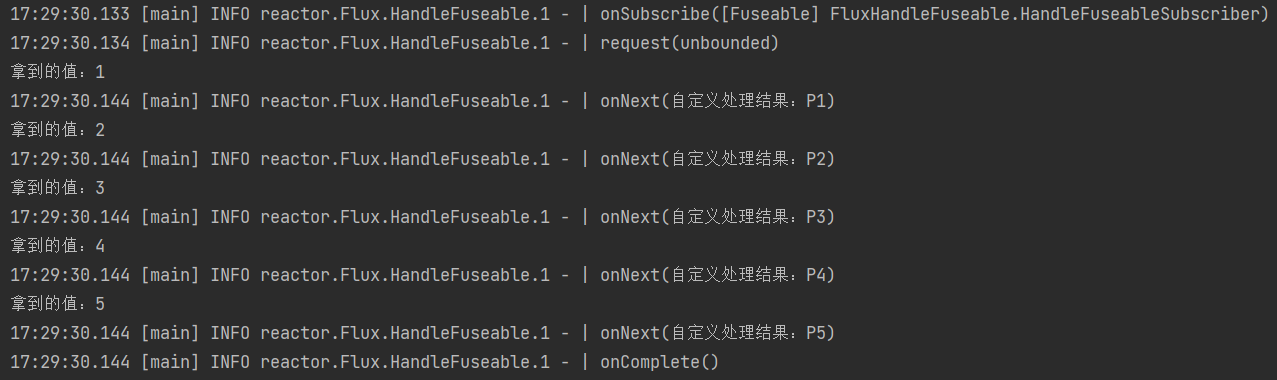
与map相似,但是map必须是映射成同类型的元素,而handle可以任意操作。handle后,流中可能有不同类型的数据。
自定义线程调度
默认是用当前线程,生成整个流、发布流、流操作
publishOn:改变发布者所在线程池
subscribeOn:改变订阅者所在线程池
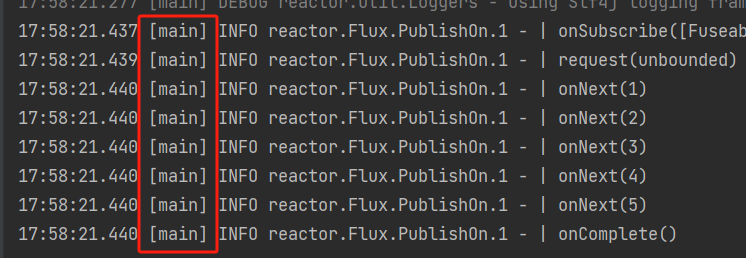
Schedulers.immediate(),当没有指定的时候默认用的就是这个方法:无执行上下文。既当前线程运行所有操作Flux.range(1,5) .publishOn(Schedulers.immediate()) .log() .subscribe();执行结果:都是同一个线程
-
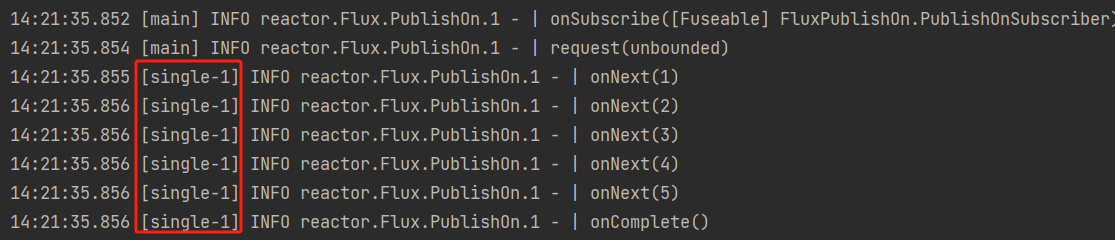
Schedulers.single(),使用固定的一个单线程执行所有操作Flux.range(1,5) .publishOn(Schedulers.single()) .log() .subscribe();执行结果:
-
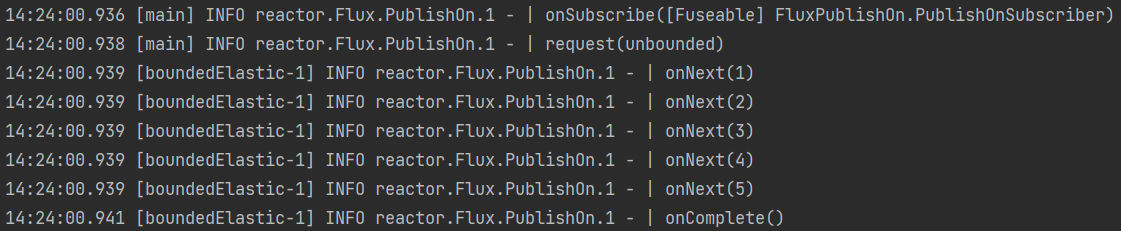
Schedulers.boundedElastic(),使用固定大小的线程池执行所有操作。默认是:线程池中有 10*cpu核心个数的线程,队列默认为100k,KeepAliveTime默认为60s。Flux.range(1,5) .publishOn(Schedulers.boundedElastic()) .log() .subscribe();执行结果:
-
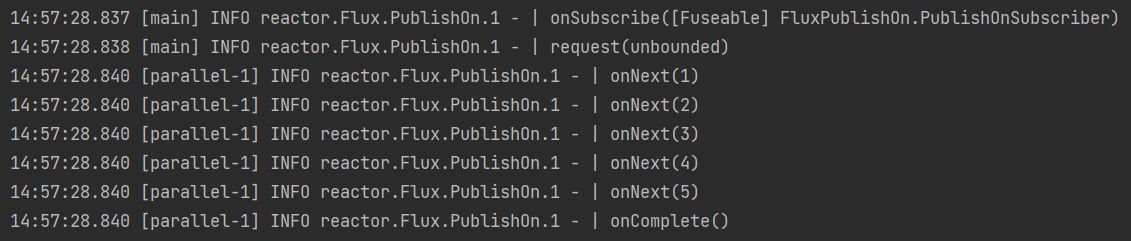
Schedulers.parallel(),并发池Flux.range(1,5) .publishOn(Schedulers.parallel()) .log() .subscribe();执行结果:
-
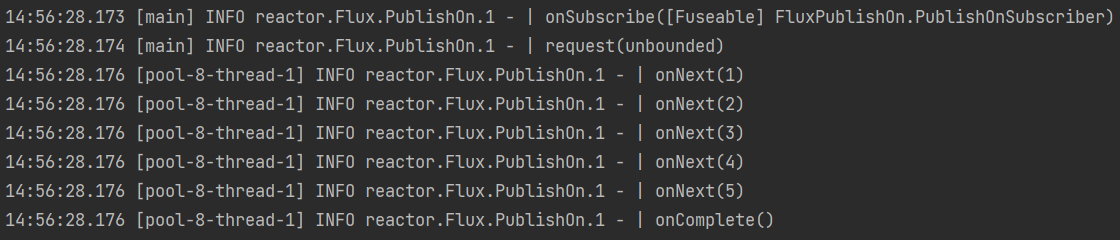
Schedulers.fromExecutor(new ThreadPoolExecutor(4,8,60, TimeUnit.SECONDS,new LinkedBlockingQueue<>(1000))),自定义线程池。fromExecutor方法里的参数是自己自定义的。Flux.range(1,5) .publishOn(Schedulers.fromExecutor(new ThreadPoolExecutor(4,8,60, TimeUnit.SECONDS,new LinkedBlockingQueue<>(1000)))) .log() .subscribe();执行结果:




评论